What is Metastore

Olivia Owen
Published Apr 03, 2026
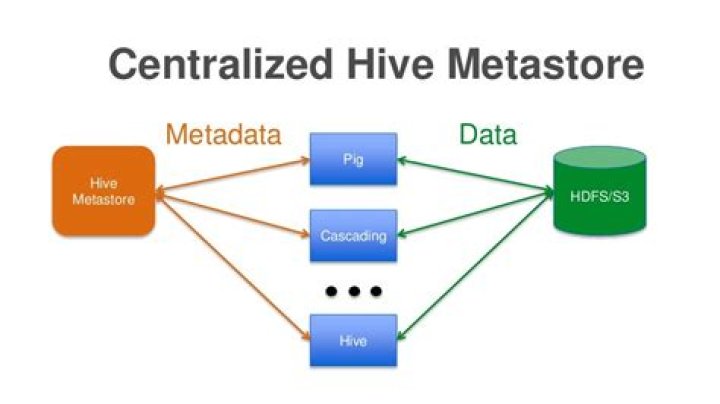
Metastore is the central repository of Apache Hive metadata. It stores metadata for Hive tables (like their schema and location) and partitions in a relational database. It provides client access to this information by using metastore service API. … A service that provides metastore access to other Apache Hive services.
What is Hive Metastore?
Hive metastore (HMS) is a service that stores metadata related to Apache Hive and other services, in a backend RDBMS, such as MySQL or PostgreSQL. … All connections are routed to a single RDBMS service at any given time. HMS talks to the NameNode over thrift and functions as a client to HDFS.
What is Metastore in Databricks?
Every Azure Databricks deployment has a central Hive metastore accessible by all clusters to persist table metadata. Instead of using the Azure Databricks Hive metastore, you have the option to use an existing external Hive metastore instance.
Where is Metastore stored in Hive?
Finally the location of the metastore for hive is by default located here /usr/hive/warehouse .What is the default Metastore in Hive?
Derby is the default database for the embedded metastore.
What is glue Metastore?
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores. …
What is spark Metastore?
A Hive metastore warehouse (aka spark-warehouse) is the directory where Spark SQL persists tables whereas a Hive metastore (aka metastore_db) is a relational database to manage the metadata of the persistent relational entities, e.g. databases, tables, columns, partitions.
How do I find Metastore in Hive?
You can query the metastore schema in your MySQL database. Something like: mysql> select * from TBLS; More details on how to configure a MySQL metastore to store metadata for Hive and verify and see the stored metadata here.Why Hive Metastore is Rdbms?
Hive stores metadata information in the metastore using RDBMS instead of HDFS. The reason for choosing RDBMS is to achieve low latency as HDFS read/write operations are time consuming processes. Q) Whenever we run a Hive query, a new metastore_db is created.
What is partition in Hive?The partitioning in Hive means dividing the table into some parts based on the values of a particular column like date, course, city or country. … In such a case, we can adopt the better approach i.e., partitioning in Hive and divide the data among the different datasets based on particular columns.
Article first time published onWhat is pool in Databricks?
June 29, 2021. Databricks pools reduce cluster start and auto-scaling times by maintaining a set of idle, ready-to-use instances. When a cluster is attached to a pool, cluster nodes are created using the pool’s idle instances.
What is hive and its architecture?
Architecture of Hive Hive is a data warehouse infrastructure software that can create interaction between user and HDFS. The user interfaces that Hive supports are Hive Web UI, Hive command line, and Hive HD Insight (In Windows server). Meta Store.
Does Databricks have hive?
Apache Spark SQL in Databricks is designed to be compatible with the Apache Hive, including metastore connectivity, SerDes, and UDFs.
What is catalog in Hive?
The Hive catalog serves two purposes: … It is a persistent storage for pure Flink metadata. It is an interface for reading and writing existing Hive tables.
What is called metadata?
Data that provide information about other data. Metadata summarizes basic information about data, making finding & working with particular instances of data easier. Metadata can be created manually to be more accurate, or automatically and contain more basic information.
Can multiple users use one Metastore?
The embedded metastore service communicates with the metastore database over JDBC. This mode allows us to have multiple Hive sessions, i.e. multiple users can use the metastore at the same time.
Where is Hive Metastore URI?
While in the Hive service, click Service Actions > Add Hive Metastore. Select a host and then confirm. Start the Hive service. Metastore clients find the URI of the metastore from the configuration parameter hive.
Does Spark have its own Metastore?
Spark bootstraps a pseudo-Metastore (embedded Derby DB) for internal use, and optionally uses an actual Hive Metastore to read/write persistent Hadoop data.
How do I change Metastore in Hive?
- To Maintain a single copy of Embedded Metastore:
- Configuring Local Metastore:
- Start Hive CLI service:
- Start Hive Thrift server:
- Start Hive Metastore service:
- Configure Remote Metastore:
Is APIs are glue?
Integrating existing services to their applications through APIs has allowed developers to build increasingly complex and capable applications, which has led to the rise of giant Web services and mobile applications. Because of this, APIs are often referred to as the glue that holds the digital world together.
What is Athena Metastore?
Athena Data Connector for External Hive Metastore includes support for catalog registration API operations and metadata API operations. Catalog registration – Register custom catalogs for external Hive metastores and federated data sources.
What is a glue job?
An AWS Glue job encapsulates a script that connects to your source data, processes it, and then writes it out to your data target. Typically, a job runs extract, transform, and load (ETL) scripts. … AWS Glue triggers can start jobs based on a schedule or event, or on demand.
Why Metastore is not stored in HDFS?
A file system like HDFS is not suited since it is optimized for sequential scans and not for random access. So, the metastore uses either a traditional relational database (like MySQL, Oracle) or file system (like local, NFS, AFS) and not HDFS.
Which query language is used in hive?
Hive queries are written in HiveQL, which is a query language similar to SQL. Hive allows you to project structure on largely unstructured data. After you define the structure, you can use HiveQL to query the data without knowledge of Java or MapReduce.
Why Metastore is used in between query processing?
For syntax and semantic analysis or validation for your query, even in the execution engine, it contains the metastore before executing your queries, so all these responses to speed up the processing between these components an RDBMS is used as a metastore here in Hive.
What is SDS in Hive?
In Hive Metastore tables: … “PARTITIONS” stores the information of Hive table partitions. “SDS” stores the information of storage location, input and output formats, SERDE etc. Both “TBLS” and “PARTITIONS” have a foreign key referencing to SDS(SD_ID).
What is the difference between local and remote Metastore?
In comparison with the Local mode, there is one benefit of using the Remote mode, that is Remote mode does not need the administrator to share JDBC login information for the metastore database along with each Hive user, but local mode does.
What is bucketing in Hive with example?
Bucketing in hive is the concept of breaking data down into ranges, which are known as buckets, to give extra structure to the data so it may be used for more efficient queries. The range for a bucket is determined by the hash value of one or more columns in the dataset (or Hive metastore table).
What is static partitioning?
Hive Static Partitioning. Insert input data files individually into a partition table is Static Partition. … Static Partition saves your time in loading data compared to dynamic partition. You “statically” add a partition in the table and move the file into the partition of the table.
What is partitioning and bucketing?
Partitioning helps in elimination of data, if used in WHERE clause, where as bucketing helps in organizing data in each partition into multiple files, so as same set of data is always written in same bucket.
What is indexing in Hive?
Introduction to Indexes in Hive. Indexes are a pointer or reference to a record in a table as in relational databases. Indexing is a relatively new feature in Hive. In Hive, the index table is different than the main table. Indexes facilitate in making query execution or search operation faster.