What are nodes in big data

Rachel Hunter
Published Apr 10, 2026
A node is a process running on a virtual or physical machine or in a container. … That would be suitable for, say, installing Hadoop on one machine just to learn it. When you run Hadoop in local node it writes data to the local file system instead of HDFS (Hadoop Distributed File System).
What are data nodes?
A data node is an appliance that you can add to your event and flow processors to increase storage capacity and improve search performance. … Each data node can be connected to only one processor, but a processor can support multiple data nodes.
What are cluster and nodes?
In Hadoop distributed system, Node is a single system which is responsible to store and process data. Whereas Cluster is a collection of multiple nodes which communicates with each other to perform set of operation. Or. Multiple nodes are configured to perform a set of operations we call it Cluster.
What are nodes in Hadoop?
A Hadoop cluster is a collection of computers, known as nodes, that are networked together to perform these kinds of parallel computations on big data sets. … Hadoop clusters consist of a network of connected master and slave nodes that utilize high availability, low-cost commodity hardware.What is name node and data node in big data?
Key Points. The main difference between NameNode and DataNode in Hadoop is that the NameNode is the master node in Hadoop Distributed File System (HDFS) that manages the file system metadata while the DataNode is a slave node in Hadoop distributed file system that stores the actual data as instructed by the NameNode.
What is nodes in data structure?
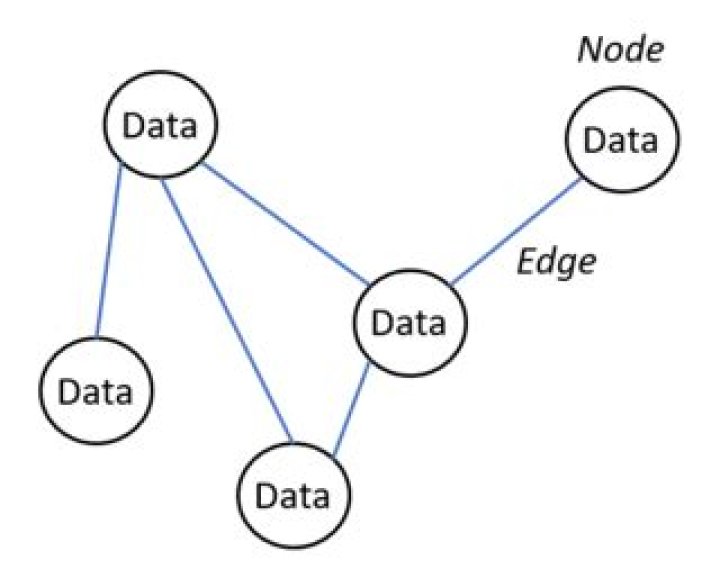
A node is a basic unit of a data structure, such as a linked list or tree data structure. Nodes contain data and also may link to other nodes. Links between nodes are often implemented by pointers.
What is node in a network?
In telecommunications networks, a node (Latin: nodus, ‘knot’) is either a redistribution point or a communication endpoint. … A physical network node is an electronic device that is attached to a network, and is capable of creating, receiving, or transmitting information over a communication channel.
What is namespace and Blockpool?
A Namespace and its block pool together are called Namespace Volume. It is a self-contained unit of management. When a Namenode/namespace is deleted, the corresponding block pool at the Datanodes is deleted. Each namespace volume is upgraded as a unit, during cluster upgrade.What is a cluster in big data?
A Hadoop cluster is a special type of computational cluster designed specifically for storing and analyzing huge amounts of unstructured data in a distributed computing environment. … Hadoop clusters are known for boosting the speed of data analysis applications.
How many types of nodes are there in Hadoop?Hadoop and HBase clusters have two types of machines: masters and slaves. Masters — HDFS NameNode, YARN ResourceManager, and HBase Master. Slaves — HDFS DataNodes, YARN NodeManagers, and HBase RegionServers. The DataNodes, NodeManagers, and HBase RegionServers are co-located or co-deployed for optimal data locality.
Article first time published onWhat are nodes in Server?
A node is any physical device within a network of other tools that’s able to send, receive, or forward information. … It’s called the computer node or internet node. Modems, switches, hubs, bridges, servers, and printers are also nodes, as are other devices that connect over Wi-Fi or Ethernet.
What is nodes in cloud?
Node in Cloud Computing is a connection point, either a redistribution point or an end point for data transmissions in general. … Node is actually a terminology that is derived from Networking. From Networking it was used in Grid Computing, then Virtualization and from from Virtualization in Cloud Computing.
Why does node have 3 clusters?
Having a minimum of three nodes can ensure that a cluster always has a quorum of nodes to maintain a healthy active cluster. With two nodes, a quorum doesn’t exist. Without it, it is impossible to reliably determine a course of action that both maximizes availability and prevents data corruption.
What data is stored in name node?
NameNode only stores the metadata of HDFS – the directory tree of all files in the file system, and tracks the files across the cluster. NameNode does not store the actual data or the dataset. The data itself is actually stored in the DataNodes.
What is Pig and Hive?
Pig is a Procedural Data Flow Language. Hive is a Declarative SQLish Language. 4. It was developed by Yahoo. It was developed by Facebook.
What is Hadoop in Big data?
Apache Hadoop is an open source framework that is used to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data. Instead of using one large computer to store and process the data, Hadoop allows clustering multiple computers to analyze massive datasets in parallel more quickly.
What is node example?
1. In data communication, a node is any active, physical, electronic device attached to a network. … Examples of nodes include bridges, switches, hubs, and modems to other computers, printers, and servers. One of the most common forms of a node is a host computer; often referred to as an Internet node.
What are nodes and links?
Answer: A node is an individual processing unit , it has capabaility to communicate with other nodes on demand , process the information it receives. … A link is a physical and logical network component used to interconnect hosts or nodes in the network.
How many nodes are on the Internet?
Fifty billion internet nodes predicted by 2020 The dramatic growth of the Internet over the last 30 years has surpassed the estimates of even the most optimistic pundits. Industry experts now predict that the number of Internet-connected devices will exceed 15 billion nodes by 2015 and top 50 billion by 2020.
What is a node in waves?
All standing wave patterns consist of nodes and antinodes. The nodes are points of no displacement caused by the destructive interference of the two waves. The antinodes result from the constructive interference of the two waves and thus undergo maximum displacement from the rest position.
What does create node?
Nodes get created when a flow is deployed, they may send and receive some messages whilst the flow is running and they get deleted when the next flow is deployed. They consist of a pair of files: … an html file that defines the node’s properties, edit dialog and help text.
What are nodes and internodes?
Nodes are the regions on the stem from which leaves develop, while internodes are the regions between two nodes.
What is cluster and its types?
Clustering itself can be categorized into two types viz. Hard Clustering and Soft Clustering. In hard clustering, one data point can belong to one cluster only. But in soft clustering, the output provided is a probability likelihood of a data point belonging to each of the pre-defined numbers of clusters.
Why is K means clustering used?
The K-means clustering algorithm is used to find groups which have not been explicitly labeled in the data. This can be used to confirm business assumptions about what types of groups exist or to identify unknown groups in complex data sets.
What is snapshot in HDFS?
Overview. HDFS Snapshots are read-only point-in-time copies of the file system. Snapshots can be taken on a subtree of the file system or the entire file system. Some common use cases of snapshots are data backup, protection against user errors and disaster recovery.
What is namespace in Hadoop?
In Hadoop we refer to a Namespace as a file or directory which is handled by the Name Node. … Namespace act as a container where file name grouping and metadata which also contains things like the owners of files, permission bits, block location, size etc will be present.
What is pool in Hadoop?
Block pools are having the information about each block and each file’s data in Hadoop Cluster. Block pools are storing metadata about each blocks in memory, for faster access not on disk. … Hadoop Federation uses the concept of multiple namespaces. Namespaces are maintained by different namenodes.
What is Hadoop master node?
Master Node – Master node in a hadoop cluster is responsible for storing data in HDFS and executing parallel computation the stored data using MapReduce. Master Node has 3 nodes – NameNode, Secondary NameNode and JobTracker.
What are combiners?
A Combiner, also known as a semi-reducer, is an optional class that operates by accepting the inputs from the Map class and thereafter passing the output key-value pairs to the Reducer class. The main function of a Combiner is to summarize the map output records with the same key.
Why do we use node?
Node. js is primarily used for non-blocking, event-driven servers, due to its single-threaded nature. It’s used for traditional web sites and back-end API services, but was designed with real-time, push-based architectures in mind.
Is a browser a node?
Both the browser and Node use JavaScript as their programming language. Building an application that runs in a browser is completely different from building a Node. js application. Although the fact is always JavaScript, there are still some key differences that make the experience completely different.